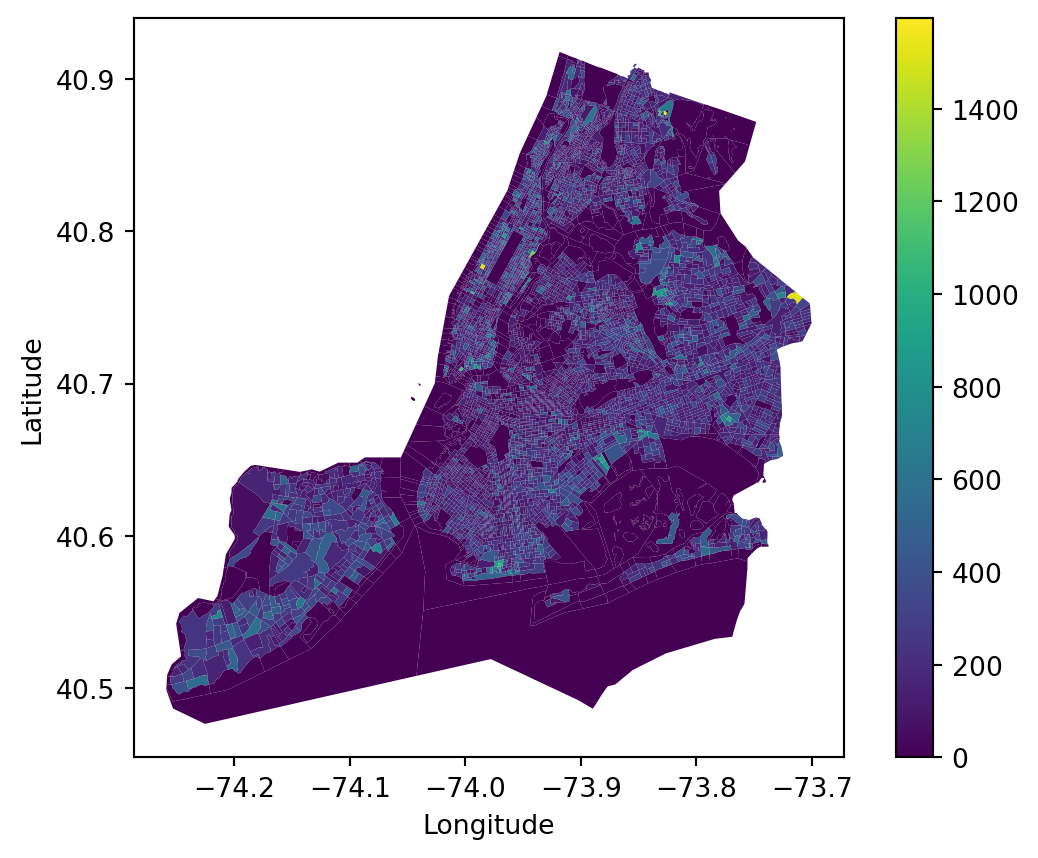
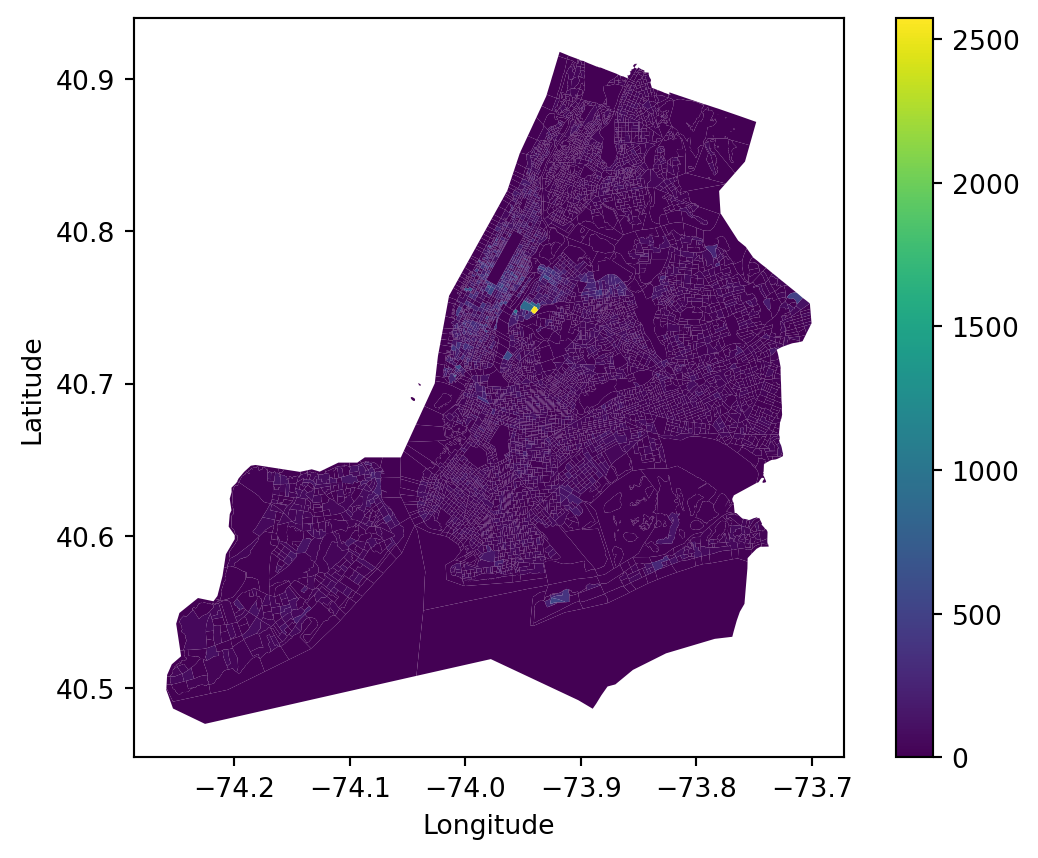
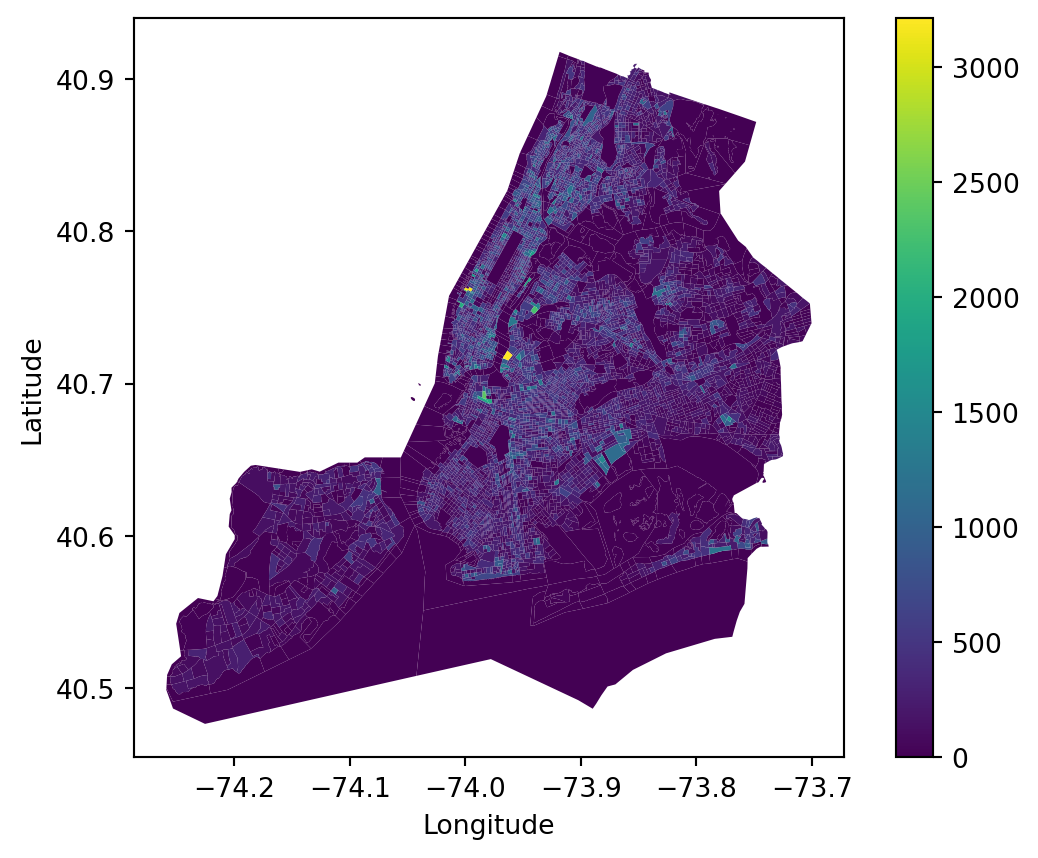
Community-based Adaptivity index is based on Rebuild by Design’s Climate Displacement in New York City report (Rebuild by Design, 2022). Moreover, we focus on the ownership rate and people within vulnerable Age Group, as displacement causes larger losses to homeowners and people older than 65 or younger than 15.
Therefore, this index is determined by six demographics and housing-related criteria, which measures how an area is subject to storm-related asset loss and life-threatening situations and leans more to social impact than the previous factors. Data are acquired from ACS API (ACS, 2022). They are:
Households with one or more people 60 years and over; Vacancy; Renter Occupation; Total Population; Median household income; Median year built.
Code
import pygrisimport geopandas as gpdimport numpy as npimport pandas as pdimport requestsimport seaborn as snsfrom matplotlib import pyplot as pltimport holoviews as hvimport hvplot.pandasimport matplotlib.font_manager as font_managerimport cenpypd.options.display.max_columns =999pd.options.display.max_colwidth =Noneavailable = cenpy.explorer.available()acs = available.filter(regex="^ACS", axis=0)available.filter(regex="^ACSDT5Y", axis=0)acs = cenpy.remote.APIConnection("ACSDT5Y2022")variables = ["NAME","B11006_002E", #Households with one or more people 60 years and over"B25002_003E", #Vacancy"B25003_003E", #Renter Occupation"B01003_001E", #Total Population"B19013_001E", #Median household income"B25035_001E", #Median year built]NYC_county_code = ["005","047","061","081","085"]NY_state_code ="36"county_codes =",".join(NYC_county_code)NYC_demo_data = acs.query( cols=variables, geo_unit="block group:*", geo_filter={"state": NY_state_code, "county": county_codes, "tract": "*"},)NYC_block_groups = pygris.block_groups( state=NY_state_code, county=NYC_county_code, year=2022)NYC_demo_final = NYC_block_groups.merge( NYC_demo_data, left_on=["STATEFP", "COUNTYFP", "TRACTCE", "BLKGRPCE"], right_on=["state", "county", "tract", "block group"],)NYC_demo_final.rename(columns={"B11006_002E": "Households with 60+","B25002_003E": "Vacancy","B25003_003E": "Renter Occupation","B01003_001E": "Total Population","B19013_001E": "Median Household Income","B25035_001E": "Median Year Built"}, inplace=True)NYC_demo_final['Households with 60+'] = pd.to_numeric(NYC_demo_final['Households with 60+'], errors='coerce').fillna(0).astype(int)NYC_demo_final['Vacancy'] = pd.to_numeric(NYC_demo_final['Vacancy'], errors='coerce').fillna(0).astype(int)NYC_demo_final['Renter Occupation'] = pd.to_numeric(NYC_demo_final['Renter Occupation'], errors='coerce').fillna(0).astype(int)NYC_demo_final['Total Population'] = pd.to_numeric(NYC_demo_final['Total Population'], errors='coerce').fillna(0).astype(int)NYC_demo_final['Median Household Income'] = pd.to_numeric(NYC_demo_final['Median Household Income'], errors='coerce').fillna(0).astype(int)median1 = NYC_demo_final['Median Household Income'].median()NYC_demo_final['Median Household Income'] = NYC_demo_final['Median Household Income'].mask(NYC_demo_final['Median Household Income'] <0, median1)NYC_demo_final['Median Year Built'] = pd.to_numeric(NYC_demo_final['Median Year Built'], errors='coerce').fillna(0).astype(int)median2 = NYC_demo_final['Median Year Built'].median()NYC_demo_final['Median Year Built'] = NYC_demo_final['Median Year Built'].mask(NYC_demo_final['Median Year Built'] <0, median2)
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\libpysal\cg\alpha_shapes.py:39: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def nb_dist(x, y):
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\libpysal\cg\alpha_shapes.py:165: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def get_faces(triangle):
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\libpysal\cg\alpha_shapes.py:199: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def build_faces(faces, triangles_is, num_triangles, num_faces_single):
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\libpysal\cg\alpha_shapes.py:261: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
def nb_mask_faces(mask, faces):
Code
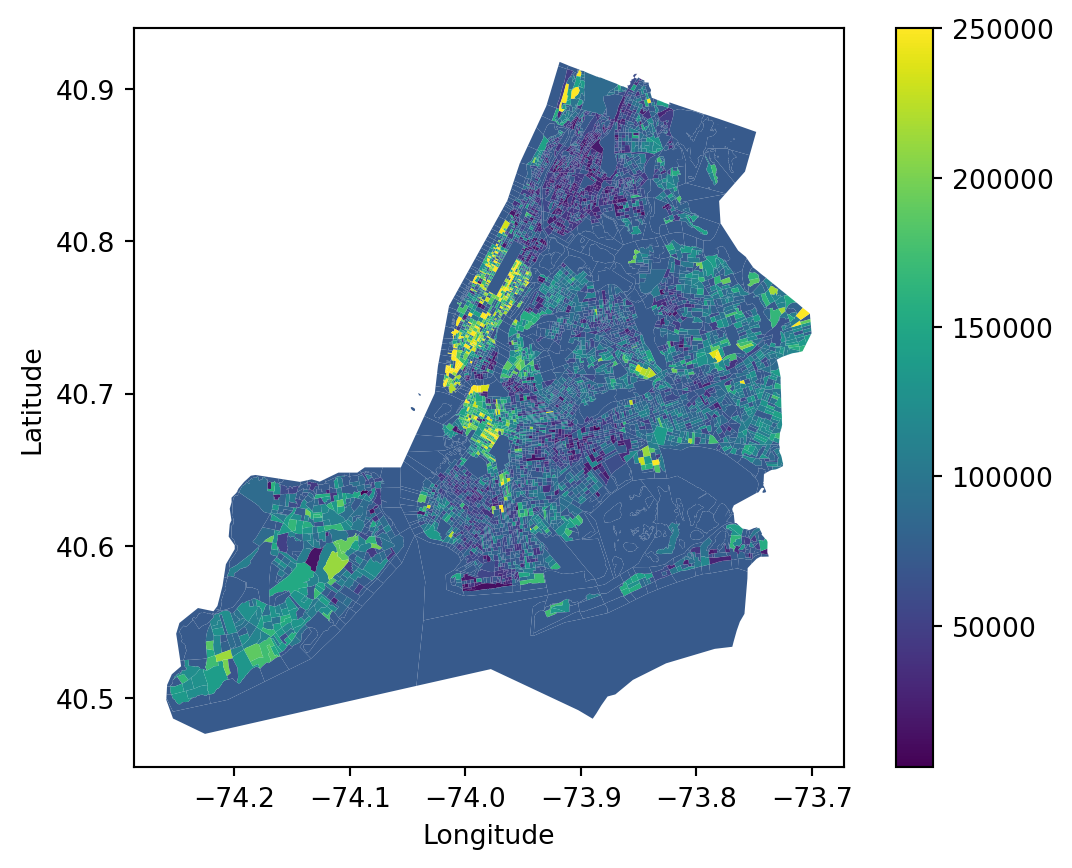
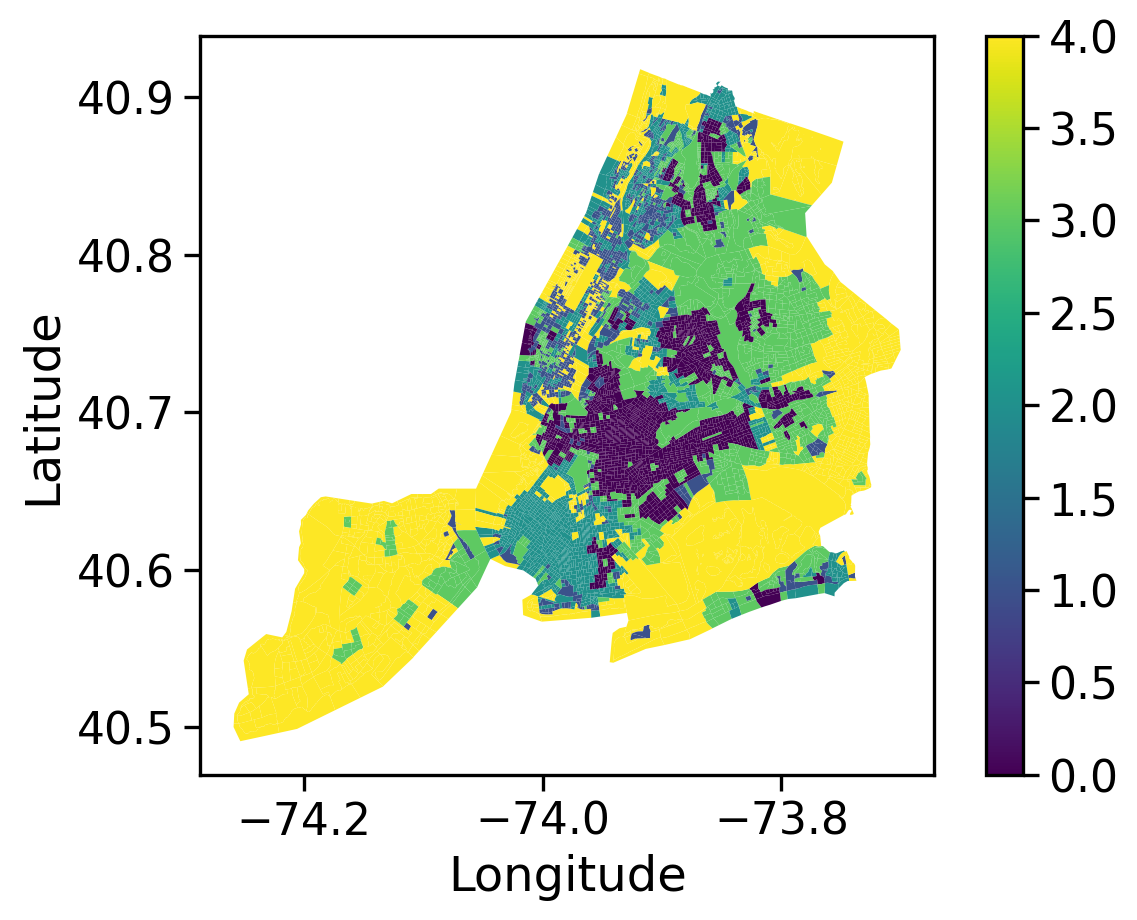
NYC_demo_final.plot(column='Households with 60+', legend=True, cmap='viridis')plt.xlabel('Longitude')plt.ylabel('Latitude')plt.show()
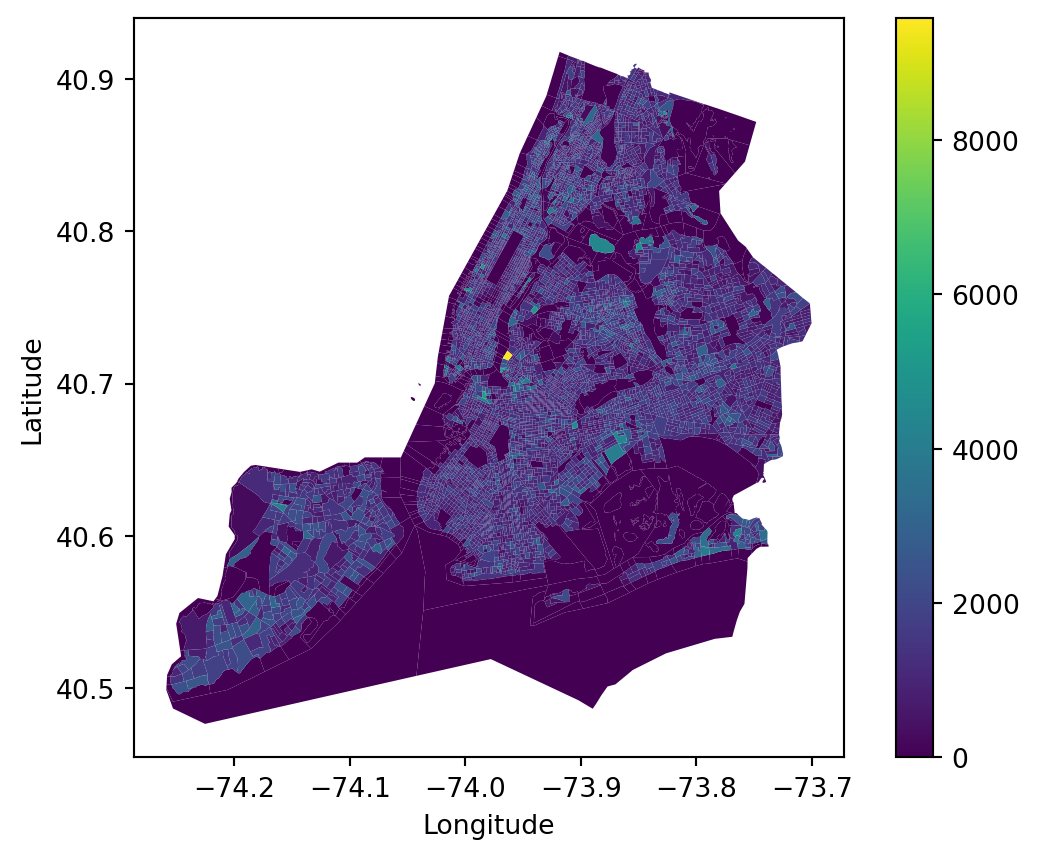
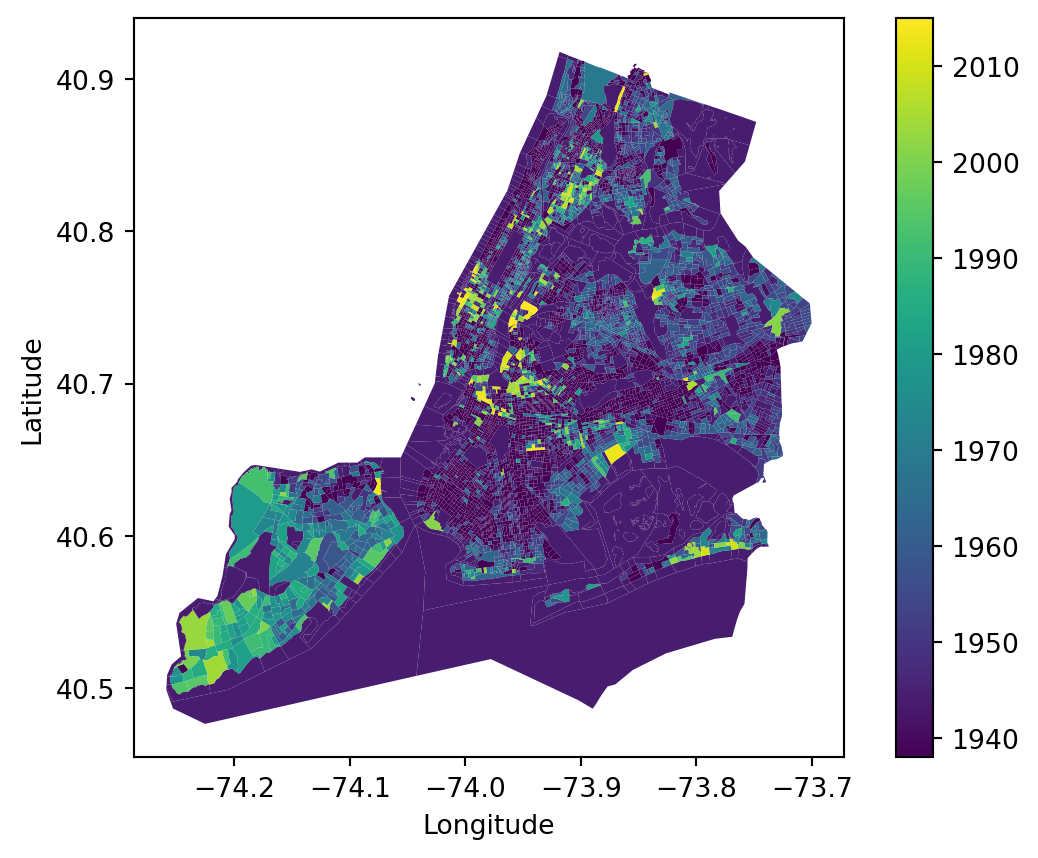
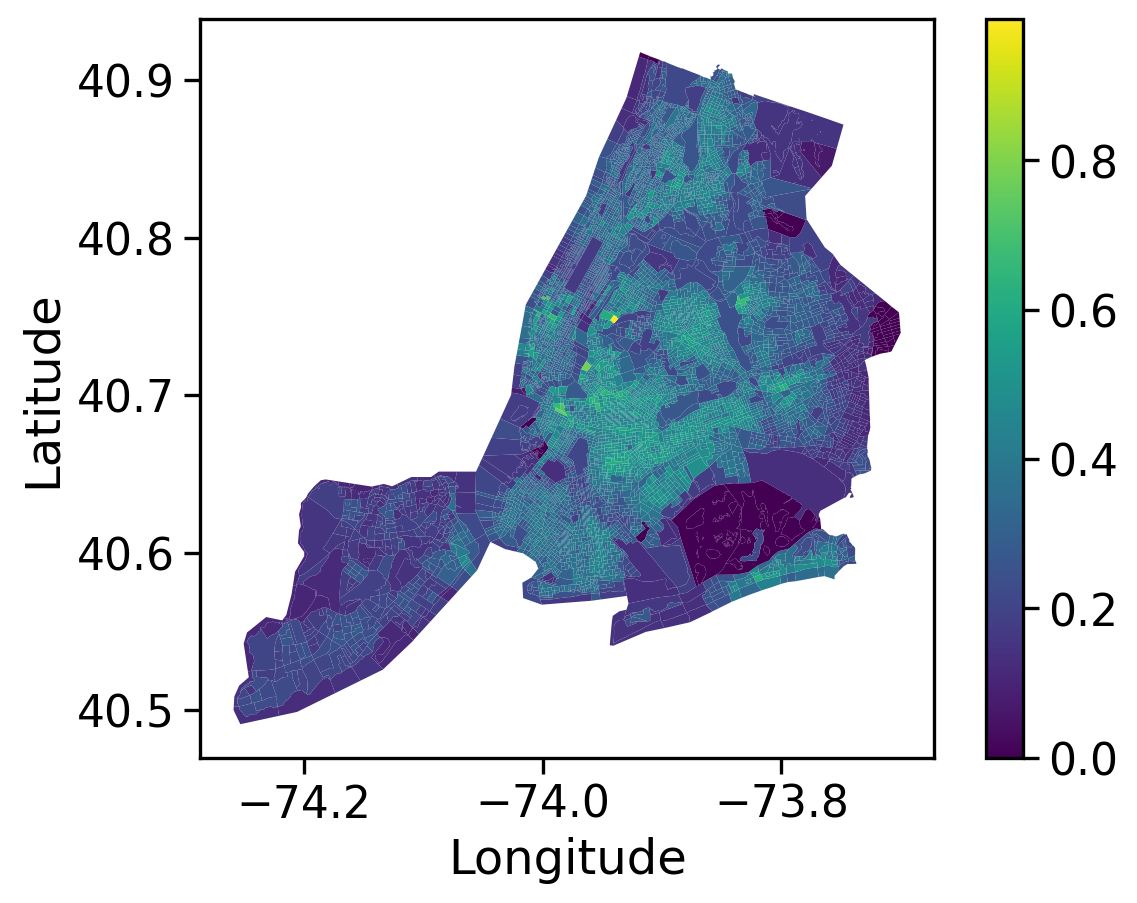
NYC_demo_final.plot(column='Median Year Built', legend=True, cmap='viridis')plt.xlabel('Longitude')plt.ylabel('Latitude')plt.show()
Median Year Built
Next, we are going to normalize these data. We generally expect less elderly people, Lower ownershiprate, higher vacancy, higher Justice 40 qualification rate represented by lower income, newer houses and smaller population size.
Code
from scipy.stats import gmeanNYC_demo_final_Normalized = NYC_demo_finalNYC_demo_final_Normalized['Households with 60+'] = NYC_demo_final_Normalized['Households with 60+']/-1000NYC_demo_final_Normalized['Vacancy'] = NYC_demo_final_Normalized['Vacancy']/400NYC_demo_final_Normalized['Renter Occupation'] = NYC_demo_final_Normalized['Renter Occupation']/1500NYC_demo_final_Normalized['Total Population'] = NYC_demo_final_Normalized['Total Population']/-6000NYC_demo_final_Normalized['Median Household Income'] = NYC_demo_final_Normalized['Median Household Income']/-200000NYC_demo_final_Normalized['Median Year Built'] = (NYC_demo_final_Normalized['Median Year Built'] -1900)/122NYC_demo_final_Normalized.index = NYC_demo_final_Normalized['GEOID']columns_to_keep = ["Households with 60+","Vacancy","Renter Occupation","Total Population","Median Household Income","Median Year Built"]new_df = NYC_demo_final_Normalized[columns_to_keep]k =-(1/np.log(new_df.shape[0]))def entropy(X):return (X*np.log(X)).sum()*kentropy = new_df.apply(entropy)dod =1- entropyw = dod/dod.sum()w.sort_values(ascending =False)
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\pandas\core\arraylike.py:402: RuntimeWarning: divide by zero encountered in log
result = getattr(ufunc, method)(*inputs, **kwargs)
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\pandas\core\arraylike.py:402: RuntimeWarning: invalid value encountered in log
result = getattr(ufunc, method)(*inputs, **kwargs)
Median Year Built 0.455488
Renter Occupation 0.341362
Vacancy 0.208312
Households with 60+ -0.001721
Total Population -0.001721
Median Household Income -0.001721
dtype: float64
TOPSIS, standing for Technique for Order of Preference by Similarity to Ideal Solution, is a method used in multi-criteria decision analysis purposed by Hwang et al. (Yoon & Hwang, 1995). It involves comparing a set of alternatives against a defined set of criteria. This method finds widespread application in various industries within the business sector, being particularly useful whenever there’s a need to make an analytical decision grounded in collected data. (Lai, et al., 1994). The entropy weight method is an effective method to accurately weigh the relative importance of the identified criteria for TOPSIS computation, the base of which is the volume of information to calculate the index’s weight (Dehdasht, et al., 2020).
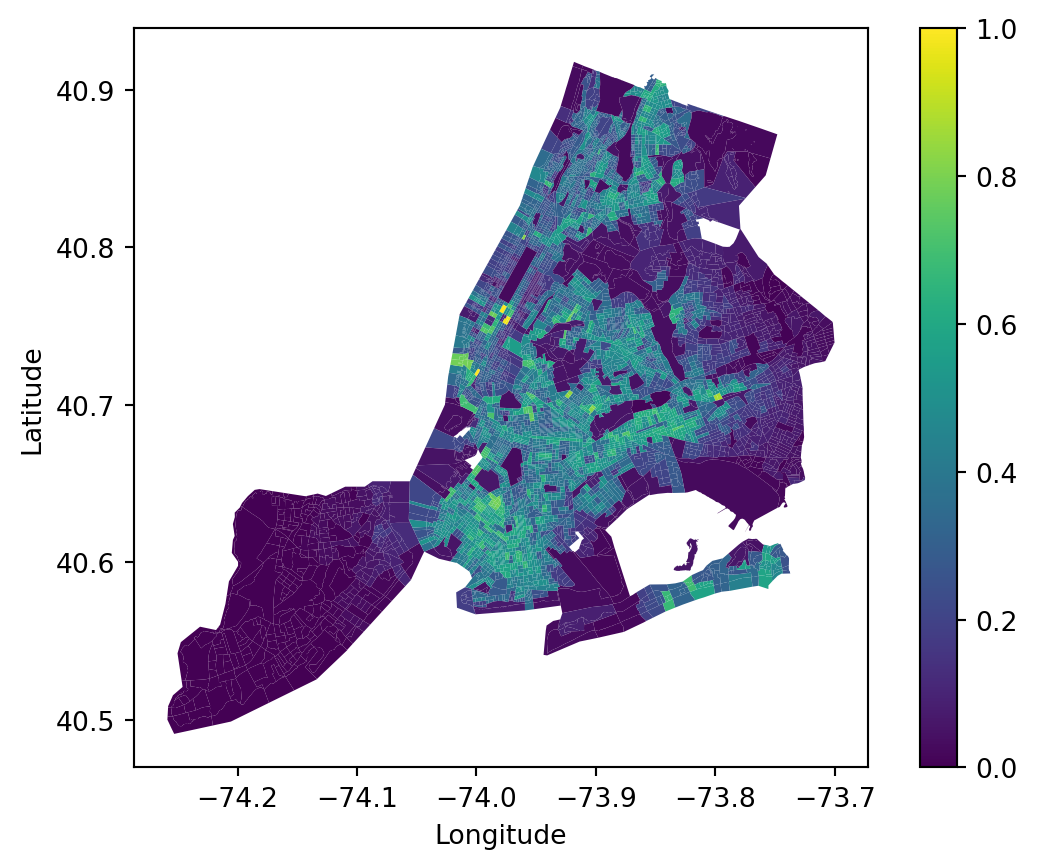
Listed above is a set of Entropy-TOPSIS calibrated weight based on pattern of data. Among these variables, Median Year Built,Renter Occupation and Vacancy are of significant importance. So we are going to do a weighted overlay.
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\geopandas\geodataframe.py:1538: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
super().__setitem__(key, value)
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\pandas\core\arraylike.py:402: RuntimeWarning: divide by zero encountered in log
result = getattr(ufunc, method)(*inputs, **kwargs)
Adaptivity 0.353072
ADAPTIVE 0.328961
DEVELOPMENT 0.317967
dtype: float64
Now we have the new calibrated weight. We can move on to the next step.
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\geopandas\geodataframe.py:1538: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
super().__setitem__(key, value)
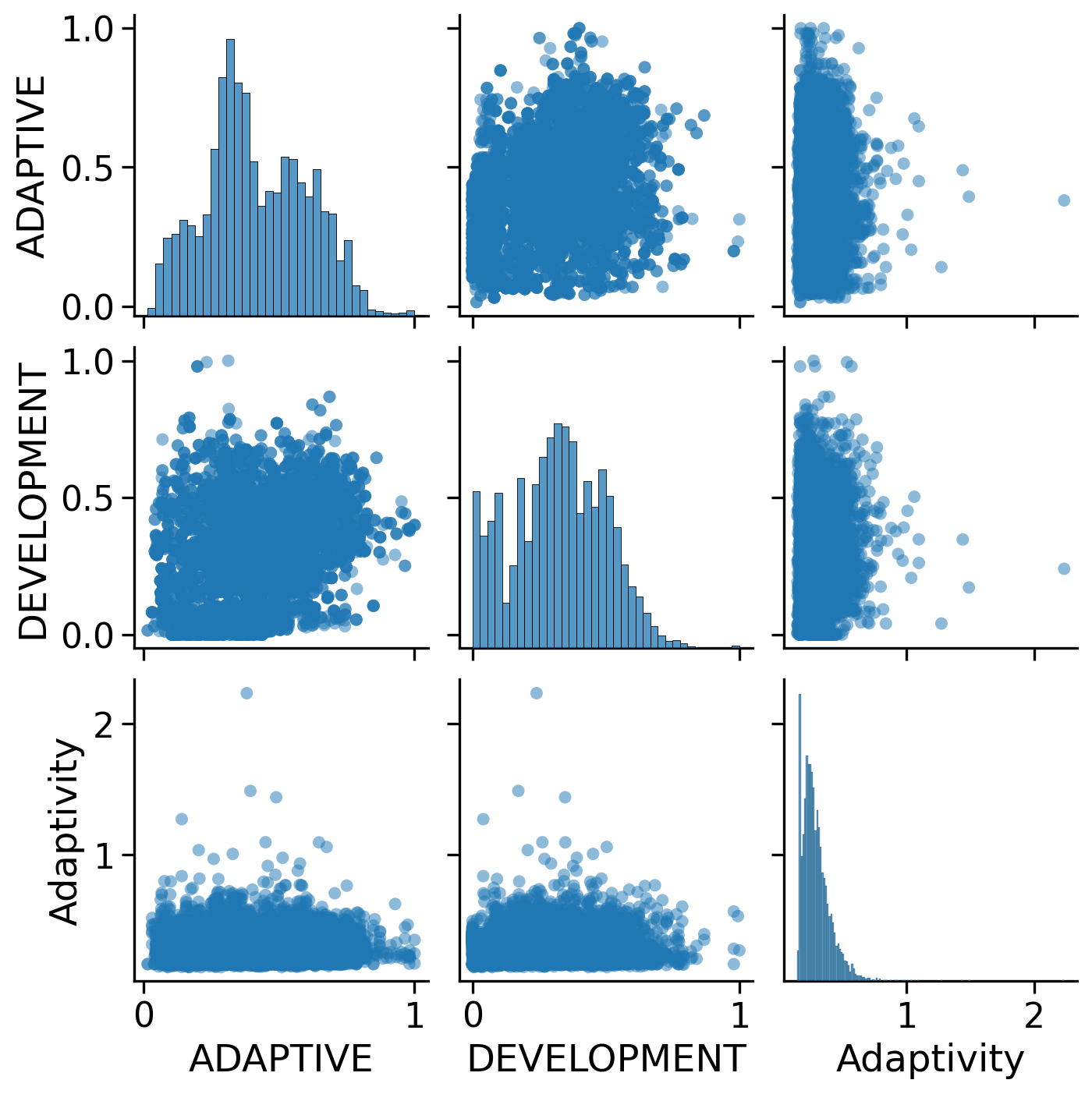
The conclusion dataframe is here. The next step is K-means grouping in two ways, thus checking if calibrated weight reflect the types of communities well.
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\seaborn\axisgrid.py:1507: UserWarning: Ignoring `palette` because no `hue` variable has been assigned.
func(x=vector, **plot_kwargs)
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\seaborn\axisgrid.py:1507: UserWarning: Ignoring `palette` because no `hue` variable has been assigned.
func(x=vector, **plot_kwargs)
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\seaborn\axisgrid.py:1507: UserWarning: Ignoring `palette` because no `hue` variable has been assigned.
func(x=vector, **plot_kwargs)
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\seaborn\axisgrid.py:1609: UserWarning: Ignoring `palette` because no `hue` variable has been assigned.
func(x=x, y=y, **kwargs)
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\seaborn\axisgrid.py:1609: UserWarning: Ignoring `palette` because no `hue` variable has been assigned.
func(x=x, y=y, **kwargs)
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\seaborn\axisgrid.py:1609: UserWarning: Ignoring `palette` because no `hue` variable has been assigned.
func(x=x, y=y, **kwargs)
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\seaborn\axisgrid.py:1609: UserWarning: Ignoring `palette` because no `hue` variable has been assigned.
func(x=x, y=y, **kwargs)
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\seaborn\axisgrid.py:1609: UserWarning: Ignoring `palette` because no `hue` variable has been assigned.
func(x=x, y=y, **kwargs)
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\seaborn\axisgrid.py:1609: UserWarning: Ignoring `palette` because no `hue` variable has been assigned.
func(x=x, y=y, **kwargs)
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\seaborn\axisgrid.py:118: UserWarning: The figure layout has changed to tight
self._figure.tight_layout(*args, **kwargs)
C:\Users\Josh Williamson\AppData\Local\Temp\ipykernel_23836\890882115.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
Conclusion.fillna(0, inplace=True)
D:\Mamba\envs\musa-550-fall-2023\lib\site-packages\geopandas\geodataframe.py:1538: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
super().__setitem__(key, value)